

On AI [3]: Why Approximating Probably Won’t be Enough...
If you like what you’re reading, consider a paid subscription to support seeing more. This series will continue to be FREE, as will all of my articles. But my novels and a couple extras can be accessed behind the paywall… or you can just chip in for the sake of it. I won’t stop you.
Anyway, please enjoy and hopefully you learn something…
If you haven’t read the previous article, this one is a direct continuation. I won’t stop you from plowing ahead anyway, but just a fair warning…

I drew the thumbnail art this time for contrast. I’m not from Texas, but I have a friend who is. And he said Quacksimus, the Duck King of Texas, eats rattlesnakes, has a cowboy hat, is friend to beavers, and his symbol is both the Alamo and Whataburger.
And then my other friend sent a picture of the gladiator guy with a duck head photoshopped over him.
This is now clearly the TRUE Quacksimus.
…And with that very important point out of the way, let us move on…
The Two Major Barriers
You could perhaps take a more fine-toothed brush to the problem, but the way I see it, the two greatest factors keeping computers from reaching even a satisfactory approximation of AGI are:
Defining a “Retina” standard of human intelligence to aim for
Keeping the resource costs at an attainable level
The first pertains to our ability to even comprehend what we’re trying to build. While spontaneous inspiration is a common source of innovation, it is not until such inspiration arrives that the resulting technologies can be built. Engineering is what we’re doing and it goes very poorly when your plans are written by monkeys with typewriters. While the source of the plans may often spring up spontaneously, there’s still a plan.
We don’t have a plan for AGI yet. At least, not one with a well-defined endpoint. And if we can’t define our endpoint, we can’t engineer our way to it. But I will get into the details in a moment…
The second challenge has already been mentioned, but it really needs to be emphasized and explored in some detail. Despite everything I’ve said about the fundamental insufficiency of computers for modelling human intelligence, if an imperfect model is acceptable—as it often is—this is what I believe will ultimately keep computers from being even just “good enough.”
Now, let’s get into the details…
Challenge #1: Defining a “Retina” Standard for Intelligence
Explaining the standard
For technologies that are only interacting with humans at a sensory level—like electronic displays we’ve used as examples today—we can actually derive some pretty well-defined and universal standards for “good enough.” The physical senses, after all, deal with physical things, and we have good methods for measuring those. Thus, we test large and diverse samples of the human population to determine the limits of each of our senses (out to the third standard deviation to be safe, but practical), then set those limits as the goal for our technical specifications.
For display resolution, one of these standards is called “retina.” That is, the point where the individual pixels are smaller than what our retinas can distinguish (at the intended viewing distance). This is really nifty, as it is something can be defined by an objective metric which holds true for all of humanity—save perhaps the most extreme outliers.
…To mention the potential elephant in the room, yes, the specific term “Retina” display is an Apple trademark, and their definition given is actually a bit more relaxed than what some experts would agree with—that is, their “Retina” is about 58 pixels per degree of vision, whereas some would argue it should be as high as 100 PPD. Nevertheless, their arguments are not “whether or not the point exists,” but “whether we should set the standard at what’s good enough for 99.9% of the population or a full 100%.”
For human intelligence, we’re still at the point of arguing whether or not “the point exists.” Though, we have made progress.
An early attempt
The idea of “settling” for an approximation of a human intelligence is not a recent one. One of the most well known thinkers on the question of AI, Alan Turing, proposed exactly this with the test that came to be named after him: the Turing Test. For decades this was the most well known watermark for when a machine had reached the point of sophistication that it could be called “intelligent.”
The short and simplified explanation of the test is quite simple. You have a “judge,” and he exchanges messages back and forth with a machine and another person—anonymously, of course. If the judge can’t figure out that one of the two is a machine, then the machine has passed the test and is an “intelligent” machine. Or rather, as Turing puts it, a machine that can imitate a human.
GenAI can pass this test. And that is a tremendous feat. Yet, it became quite obvious once it did, that appearing intelligent is not a sufficient substitute for being intelligent—not enough to be called an AGI, anyway. It has proven to be sufficient enough to be useful for targeted, optimized use cases (more on that later), but there is no “generality” to it. It must be limited in scope to pass the test. That scope can still be as wide as a casual conversation, but much wider and the illusion breaks.
It turns out—as anyone would predict, including probably Turing, since generality does not seem to have been the point of the test—that the context of the conversation makes a very large difference on how difficult it is to pass. Even we humans will often fail such a test, and then we get labelled as “fake” or “insincere.”
In that way, I suppose, you could say computers can mark another notch on their belts for matching us. Unfortunately, matching our failures isn’t really the purpose of this exercise. We want them to match our best.
Regardless, since the Turing test has quantifiable target to aim for, only subjective assessments, it doesn’t work as a standard for what we want to approximate.
AIming higher
Our system can’t merely imitate a conversation or imagine up an image. We need to start the most complete picture of human intelligence and then work our way down. That is, we need to target the highest forms of reasoning man is capable of. Things like writing great poetry or inventing and proving novel scientific theories.
These are all intellectual activities that humans are capable of, and are expected of a true intelligence. While an approximation is afforded gaps in the details, the intent is that those line up with our gaps in perception well enough that we can’t effectively notice the difference… But it still has to complete a comparable task. If our attempts at AGI consistently spit out terrible poetry, then people are going to notice eventually—at least people with taste will. And if they never contribute independently to the body of scientific knowledge, then that also shows a discernable limit.
This leaves the prospect of a “good” approximation of AGI in a rather precarious place, as it will have to work with high-level, conceptual abstractions (like inventing mathematical formulae), but the margin of error there is… often quite low, and the ways to go wrong quite high.
As it stands, we with the best known hardware for those tasks tend to make pretty serious mistakes still. A machine with a fundamental limitation in its reasoning, trying to imitate us in those very precise tasks, is not likely to have much success at all, on its own—and independence is another necessity for “good enough” AGI.
Challenge #2: Scaling Woes

Approximation is a game of tradeoffs
As mentioned before, the thing that makes our approximations in engineering effective is that they are designed to maximize their effectiveness for specific tasks, rather than trying to “do everything right.”
If one thing is exactly the same as another thing in every way, then… they are the same thing. If one thing can do everything the other can and more, then the first is of a superior nature, and the other a lesser nature. If they have properties that are unique between each other, than they are simply of different natures.
Water and oil have different properties and different uses, but they are both liquids. If all you need is “a liquid” then either will do. If you, however, need an engine lubricant, then water may be slightly better than running dry but… It’s also going to evaporate far too quickly, among other issues (like evaporating into an expanding gas).
In fact, the oil is also just an approximation of what the car needs. Because, what’s needed, is the abstract concept of engine lubricant, not a specific material. But that level of philosophized engineering is for another day…
The first main point here is, the less your starting point looks like the thing you want, the more work it will take to get there. Pretty intuitive, yes?
And, another point, since the approximation is not the thing, there will always be a way to determine the difference.
Returning to our RGB light example, you can experience another quirk of their substitutionary nature by shining a bright “white” RGB light at physical objects. Unlike a true white light, the white composed of 3 individual wavelengths will bounce off of objects in an unnatural way that overemphasizes objects of the same specific color as those three lights.
While incredibly useful, the usefulness of an approximation is limited. RGB lights are intended to be looked at, they are not intended to be used to light a room naturally. But in the context of all the other requirements imposed by TVs, RGB light arrays are far more efficient than any light that could truly vary their wavelength and output.
And ignorance can be a factor in these efficiency equations. Research takes time and money, after all. And the process of picking and choosing between the features we need and the tradeoffs they come with, for a particular task, from a particular set of available resources, is at the heart of the discipline of Engineering.
Making our approximations as useful as possible for a given use case is the process we call optimization. It’s a topic I love to get into as a programmer, but that ought to be a topic for another day (or this article will go on far too long). So, I’ll relay on what’s been said already and the above example to stress the following principles of approximation:
An approximation implies a substitution.
You are trying to use something of one nature in place of a thing of a different nature.
No substitution is perfectly efficient, it will either have limits in usefulness or it was waste some number of resources, or both.
If the substitution was a “perfect” replacement, it would not be a substitute, it would be the thing.
The limit or waste incurred by the substitution scales with the difference between the two natures.
If two things are already very similar, then little extra work is necessary to compensate the gap.
These points are related to concepts I have touched on before.
What this means is that engineering a better approximation is a bargaining game—both with people and with physics. And right now, we’re running very short on resources to bargain with. Not just with temporary constraints like materials, energy, and manpower, but also with knowledge in the form of bumping up against the harder limits of physics.
Where we’re at
I’ve already mentioned the kind of scale GenAI is working at in terms of training data volume, but I didn’t point out the fact that the volume of data alone is only a part of the equation here. That statistics based “guessing” method we looked at? It’s not exactly quick to do when you have 900 or more descriptors you have to evaluate for all of the unique “things” in those petabytes of data.
Imagine, if you will, going through your entire local library, reading every book, recording every mention of a duck, and then making notes about what kind of qualities a duck has (using a scale from 1-10 for some selection out of 900-ish available descriptors).
Yeah, that would take a bloody long time, wouldn’t it? Even if it was just 10 books, that could take a normal person a whole afternoon to scan through for every mention of a duck and then analyze the sentences around it.
So, the storage space part of the equation is pretty impressive. You know what’s even more impressive?
Requiring so many processors to handle that data that there aren’t enough even being made to handle your workloads.
“We’ve been growing a lot and are out of GPUs,” Altman wrote. “We will add tens of thousands of GPUs next week and roll it out to the Plus tier then … This isn’t how we want to operate, but it’s hard to perfectly predict growth surges that lead to GPU shortages.” (emphasis mine)
This is not “we can’t afford enough GPUs,” this is “there don’t exist enough GPUs.”
These GPUs are coming from Nvidia, who was at one point last year the world’s most valuable company because of the GPUs they design for AI processing.
Except, actually, the chips on these GPUs are coming from TSMC… as are some of Intel’s latest processors, and most of AMD’s, and basically everyone.
TSMC is currently the forerunner in semiconductor manufacturing by a significant margin, and AI needs the forerunner to operate at the scale companies like OpenAI require. So, with a few exceptions, all of these AI companies are gunning for the same supply.
Additionally, GPU’s are not specially made AI processors. They used to be specially made Graphics processors, but now they are General Purpose Graphics Processing Units (GPGPU) that are like thousands of little CPUs bundled together. Each little “thread” of processing not as powerful individually, but absurdly powerful in parallel.
This is to say, it’s not just AI who wants them. Anyone who needs to crunch a lot of numbers quickly does. The game industry. The movie industry (effects and rendering). Car manufacturers (”smart” car features).
To throw the geopolitics variable in for fun, TSMC’s best foundries are in Taiwan. But, of course, there has never been a potential international conflict brewing around Taiwan.
Making things more difficult, the computer industry has long counted on drastic improvements in semiconductor manufacturing every two years or so to alleviate our growing processing needs. This year’s generation of GPUs, however, was unveiled to be on the exact same “processor nodes” as the generation two years prior, ending a long streak of shrinking dies for that particular sector of the chipmaking industry.
As a reminder, smaller nodes effectively mean more processing for the same amount of power and heat.
Smaller processor nodes do exist, but being “possible to make” and “effective to produce” are two different things, and things are not looking very optimistic for production.
If I haven’t mentioned it before, I will now: we’re at the point where quantum physics***, the one physical phenomenon we’re pretty sure is non-deterministic***, is wreaking havoc on our nanometer sized digital circuitry.
And as I definitely have mentioned before, computers don’t like non-determinism—particularly chaotic non-determinism—like quantum physics we can’t predict.
This is a major reason why shrinking the circuits of our computers further—what was at one time the single most effective method we’ve had for improving overall computer performance—will be exponentially more difficult. And that’s on top of the fact that the principles of electrical conductivity we’re relying on have a hard limit on minimum size, so that ship was going to hit land eventually anyway.
And to get a picture of the scale we’re already at, note that human DNA is 2 nanometers thick, or a little over 33 helium atoms. That includes not only the pairs of proteins that make up the “code”, but also the structural “rail” proteins that hold it all together. Meanwhile the smallest features of computer circuitry are getting to be about 2-4 nanometers thick. And that’s not even a whole transistor in a circuit (one of the main components), just some “part” of the circuitry.
It’s a measurement that leaves a lot of room for marketing to work with.
Don’t take this as me saying that DNA shows us the limit as far as shrinking circuits goes, as DNA’s overall mechanical structure is vastly different. But I do find it interesting to note how our biomechanical processes are at a similar scale, which means they also could contend with quantum physics. DNA, however, doesn’t run on electricity, so whatever effect that may entail is unclear (to me, at least).
For the record, it’s the misplacing of electrons that causes problems for computer processors. But we don’t need to get into that here.
The takeaway, for now, is that AI is stupid expensive to compute, we’re running out of computers right now, and the computers we do have might not get better than this.
This could change tomorrow, and we have plenty of other things we can do to “improve” computing beyond just manufacturing improvements. But the industry has been operating on the assumption that manufacturing will improve, and it’s looking like that assumption will come around to bite us sooner than later.
It may have been a bit unwise to operate off of the assumption that someone will have a spark of inspiration to solve one of the most exponentially difficult problems in engineering on a nice two year schedule. So, hopefully this is not what GenAI research is banking on.
Okay, but we’re already pretty close, right?
…Eh.
If you ask GPT, or, DeepSeek—or what have you—about something it only has a few outlier datapoints on, it will do better than you might expect (a true testament to how much data processing has occurred) but it will often have clear errors.
That becomes a bit embarrassing in light of all that information it is working with. For comparison, it’s not uncommon for a human to get through an entire career with only a single college textbook’s worth of relevant information as their basis.
To be fair to the machine, we do take in ridiculous amounts of information as well—if you were to account for all of the information our senses pick up over a lifetime. But it would also probably take you more than an entire lifetime to read, listen, and watch through everything in the Library of Congress, and any human who managed that would be expected to achieve far greater acts of intelligence than DeepSeek.
Such as attempting to summarize the qualities of a duck.
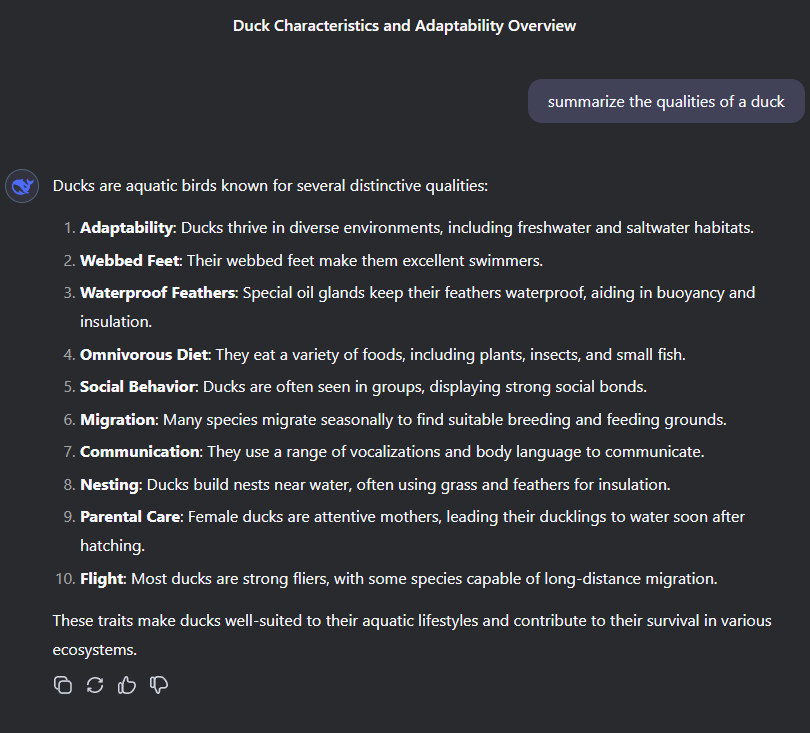
At first glance, this answer seems legitimate, if a bit overly generalized. But on closer examination, this is a summary that would probably earn an elementary schooler a B at best. #7 is pretty much a universal trait to all animate beings (but not the most offensive part about that answer), #1 makes it sound like we’re talking about a fish, and only 4 of them actually start to distinguish a duck from any other bird! It does at least consistently describe a bird after #1, so points there.
HOWEVER. The most damning failure of this whole response is that DeepSeek failed to even mention the two most IMPORTANT qualities of a duck!
Ducks QUACK
Ducks WADDLE
Utterly shameful performance.
We are not “most of the way there.”
We still have an entire ocean to cross.
Does this mean Approximation can’t give us AGI?
It’s impossible to say definitively one way or another, as one can always appeal to “hidden knowledge showing the way.” But, from what I can see and analyze…
The current technological trajectory points to it being very unlikely that computers can provide even a sufficient approximation of human intelligence.
And no, this isn’t about the duck thing.
We’re stretching the industry to its limits just to simulate a subset of one form of human reasoning optimized for certain use cases, and then we’re trying to use that simulated form of reasoning as a substitution for other forms. So, right off the bat we’re two layers of substitution deep, and that’s only at the highest level of analysis. And that kind of compounding cost increase hurts more when we’re already low on slack to work with.
That doesn’t mean that an “approximate” AGI is altogether an untenable idea. However, insisting on using computers (that is, arithmetic machines) as the basis for that approximation is perhaps doing more harm than good for many researchers.
With that said, it’s understandable why we would keep trying. Alternative technologies are in the works for a “someday.” But computers exist “today” and are powerful and mature today, and they sometimes do seem so close… today.
Just don’t talk to DeepSeek about ducks.
Thus, we keep trying to make them work…
…
…And to that end, we have other tricks we can try. Which I will cover soon.
The next article in this series, however, will take a break from the technical analysis to look at the philosophical relationship between man and thinking machines. Unfortunately, it will probably be a while before I can to it, but that will hopefully mean I’m getting some good novel writing in.
Lord knows I need to take a break from technical thinking for a bit. Golly, these last two were a labor to finish. I told myself I wasn’t going to get into academic writing, nevertheless, while writing this I kept going on hours long study tangents researching things like the precise biology of neurons.
In any case, thank you to all who have read this far. If you have any thoughts or comments on the matter or the way I’m talking about it, I would love to hear from you in the comments!
Sharing the Love
If you, likewise, need a break from brainy things, may I point you to Bruce Tomlin’s fantastic feed of pictures from Acton, Indiana?
I can tell. There is a lot of clarity I gained when I began studying apologetics, and now I am trying to read more church fathers. A friend of mine wrote an excellent article about how so often we get lost in the trends we realize many of our questions have solid, simple answers in history (transhumanism, treating the body as disposable and the mind/spirit as ultimate being another form of gnosticism, for example). When it comes to AI and recognizing what is good and useful on both a practical, material level and a spiritual, creative level, I do think examining the principles which underly a thing are more likely to generate a coherent response than examining a thing as-used (also useful info, just different.) Understanding human nature will better inform our understanding of the ethics of AI than what people can or do use it for, that is. It has been so long since I've had to formulate coherent arguments for something (and impossible on substack mobile to reference an article and comment at the same time) that I speak mainly in generalities, but this was a more interesting way to examine AI than "evil art pirate job stealer vs creative tool for the unskilled" debates I usually see. I'll be reading the other articles in this series too.
This is a wonderful analysis that brought up points I hadn't been aware of or thought of before. People complain about the power/space/heat needs/output of AI, but this gave good specific examples (chips, chip size, the actual material components) but I also very much enjoyed the philosophical discussion of approximation, teasing out categories of difference. I remember, in school, one of my professors gushing about Baudrillard's Simulacra and Simulation (which I probably read but apparently haven't retained...I didn't like that professor much), but your comparisons made sense as for when is a thing the thing, or superior, or not comparable, and how would we know. You put words to it which have helped me advance thoughts I could never quite finish in college. This made me think and learn, so thank you.